A few thingz
Joseph Basquin
19/07/2026
#datascience
Working on PDF files with Python
There are many solutions to work on PDF files with Python. Depending on whether you need to read, parse data, extract tables, modify (split, merge, crop...), or create a new PDF, you will need different tools.
Here is a quick diagram of some common tools I have used:
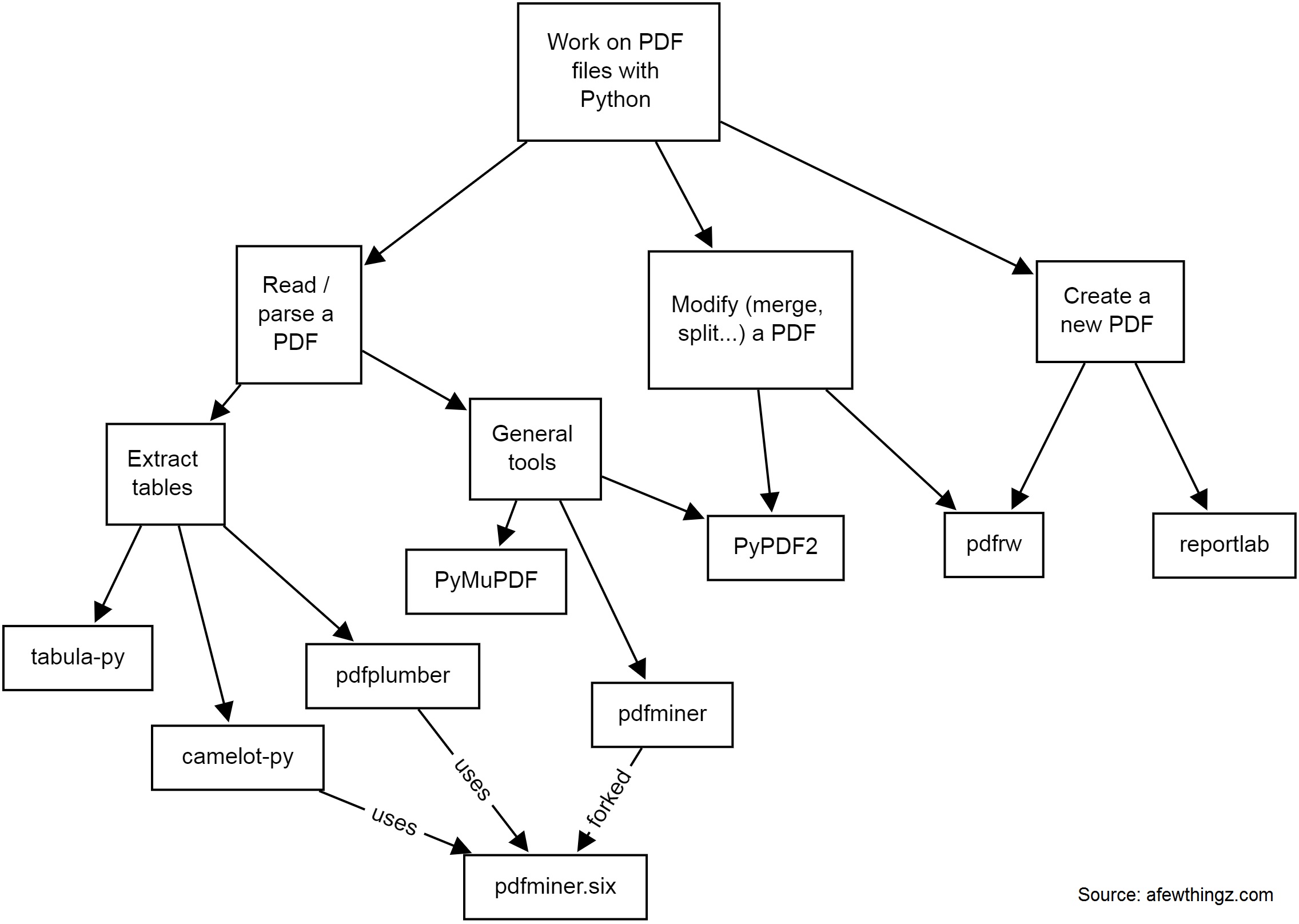
-
PyPDF2 is a free and open-source pure-python PDF library capable of splitting, merging, cropping, and transforming the pages of PDF files. It can also add custom data, viewing options, and passwords to PDF files. PyPDF2 can retrieve text and metadata from PDFs as well.
-
pdfminerandpdfminer.sixPdfminer.six is a community maintained fork of the original PDFMiner. It is a tool for extracting information from PDF documents. It focuses on getting and analyzing text data. Pdfminer.six extracts the text from a page directly from the sourcecode of the PDF. It can also be used to get the exact location, font or color of the text.
-
pdfrw is a Python library and utility that reads and writes PDF files.
-
This is a software library that lets you directly create documents in Adobe's Portable Document Format (PDF) using the Python programming language. It also creates charts and data graphics in various bitmap and vector formats as well as PDF.
-
PyMuPDF adds Python bindings and abstractions to MuPDF, a lightweight PDF, XPS, and eBook viewer, renderer, and toolkit. Both PyMuPDF and MuPDF are maintained and developed by Artifex Software, Inc.
MuPDF can access files in PDF, XPS, OpenXPS, CBZ, EPUB and FB2 (eBooks) formats, and it is known for its top performance and exceptional rendering quality.
With PyMuPDF you can access files with extensions like .pdf, .xps, .oxps, .cbz, .fb2 or .epub. In addition, about 10 popular image formats can also be handled like documents: .png, .jpg, .bmp, .tiff, etc. -
tabula-py is a simple Python wrapper of tabula-java, which can read tables in a PDF. You can read tables from a PDF and convert them into a pandas DataFrame. tabula-py also enables you to convert a PDF file into a CSV, a TSV or a JSON file.
-
Camelot is a Python library that can help you extract tables from PDFs.
pdfplumberPlumb a PDF for detailed information about each char, rectangle, line, et cetera — and easily extract text and tables.
If you need to extract data from image PDF files, it's a whole different story, and you might need to use OCR libraries like (Py)Tesseract or other tools.
Have some specific data conversion / extraction needs? Please contact me for consulting - a little script can probably automate hours of manual processing in a few seconds!
N-dimensional array data store (with labeled indexing)
What am I trying to do?
I'm currently looking for the perfect data structure for an ongoing R&D task.
I need to work with a data store as a n-dimensional array x (of dimension 4 or more) such that:
-
(1) "Ragged" array
It should be possible that
x[0, 0, :, :]is of shape (100, 100), andx[0, 1, :, :]is of shape (10000, 10000) without wasting memory by making the two last dimensions always fixed to the largest value (10000, 10000). -
(2) Labeled indexing instead of positional consecutive indexing
I also would like to be able to work with
x[19700101000000, :, :, :],x[202206231808, :, :, :], i.e. one dimension would be a numerical timestamp in format YYYYMMDDhhmmss or more generally an integer label (not a continuous0...n-1range). -
(3): Easy Numpy-like arithmetic
All of this should keep (as much as possible) all the standard Numpy basic operations, such as basic arithmetic, array slicing, useful functions such as
x.mean(axis=0)to average the data over a dimension, etc. -
(4): Random access
I would like this data store to be possibly 100 GB large. This means it should be possible to work with it without loading the whole dataset in memory.
We should be able to open the data store, modify some values and save, without rewriting the whole 100 GB file:
x = datastore.open('datastore.dat') # open the data store, *without* loading everything in memory x[20220624000000, :, :, :] = 0 # modify some values x[20220510120000, :, :, :] -= x[20220510120000, :, :, :].mean() # modify other values x.close() # only a few bytes written to disk
Possible solutions
I'm looking for a good and lightweight solution.
To keep things simple, I deliberately avoid (for now):
- BigQuery
- PySpark ("Note that PySpark requires Java 8 or later with ...")
- and more generally all cloud solutions or client/server solutions: I'd like a solution that runs on a single computer without networking
| method | ragged | non-consecutive indexing | numpy arithm. | random access for 100 GB data store | notes |
|---|---|---|---|---|---|
xarray |
? | ✓ | ✓ | no | |
sparse |
? | ✓ | ✓ | no | |
Pandas DataFrame + Numpy ndarray |
✓ | ✓ | ? | ? | (*) (**) |
Tensorflow tf.ragged.constant |
✓ | ? | ? | ? | |
Sqlite + Numpy ndarray |
? | ? | ? | ? | to be tested |
(*) serialization with parquet: doesn't accept 2D or 3D arrays:
import numpy as np, pandas as pd
x = pd.DataFrame(columns=['a', 'b'])
for i in range(100):
x.loc['t%i' % i] = [np.random.rand(100, 100), np.random.rand(2000)]
x.to_parquet('test.parquet')
# pyarrow.lib.ArrowInvalid: ('Can only convert 1-dimensional array values', 'Conversion failed for column a with type object')(**) serialization with hdf5: currently not working:
import numpy as np, pandas as pd
store = pd.HDFStore("store.h5")
df = pd.DataFrame(columns=['a', 'b'])
df.loc['t1'] = {'a': np.random.rand(100, 100), 'b': np.random.rand(2000)}
store.append('test', df)
store.close()
# TypeError: Cannot serialize the column [a] because its data contents are not [string] but [mixed] object dtypeContact me if you have ideas!
Links
Data structure for n-dimensional array / tensor such A[0, :, :] and A[1, :, :] can have different shapes
Pandas rows containing numpy ndarrays various shapes
Pandas Dataframe containing Numpy ndarray and mean
100GB data store: Pandas dataframe of numpy ndarrays: loading only a small part + avoid rewriting the whole file when doing small modifications

 twitter
twitter email
email github
github linkedin
linkedin freelancing
freelancing