Working on PDF files with Python
There are many solutions to work on PDF files with Python. Depending on whether you need to read, parse data, extract tables, modify (split, merge, crop...), or create a new PDF, you will need different tools.
Here is a quick diagram of some common tools I have used:
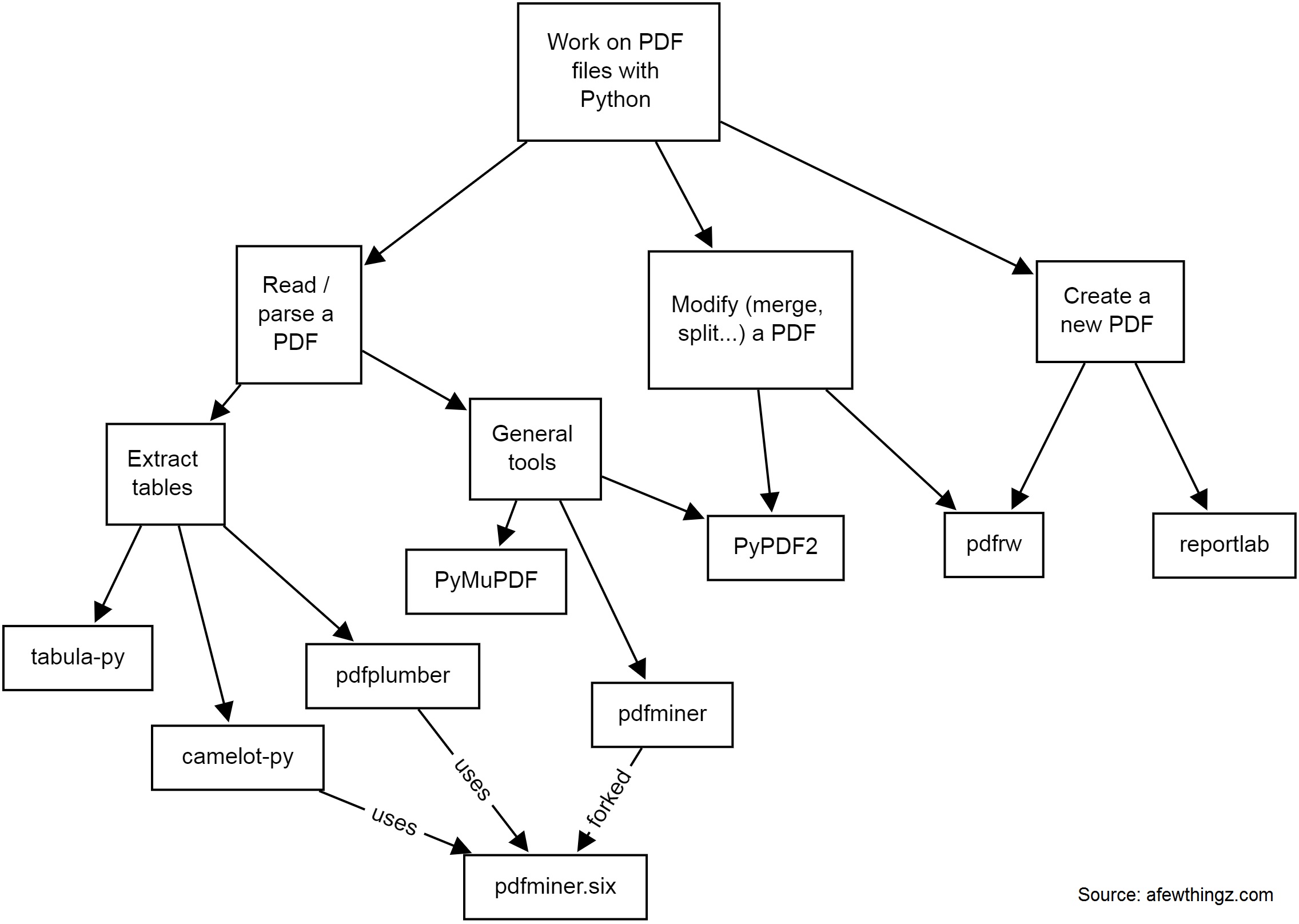
-
PyPDF2 is a free and open-source pure-python PDF library capable of splitting, merging, cropping, and transforming the pages of PDF files. It can also add custom data, viewing options, and passwords to PDF files. PyPDF2 can retrieve text and metadata from PDFs as well.
-
pdfminerandpdfminer.sixPdfminer.six is a community maintained fork of the original PDFMiner. It is a tool for extracting information from PDF documents. It focuses on getting and analyzing text data. Pdfminer.six extracts the text from a page directly from the sourcecode of the PDF. It can also be used to get the exact location, font or color of the text.
-
pdfrw is a Python library and utility that reads and writes PDF files.
-
This is a software library that lets you directly create documents in Adobe's Portable Document Format (PDF) using the Python programming language. It also creates charts and data graphics in various bitmap and vector formats as well as PDF.
-
PyMuPDF adds Python bindings and abstractions to MuPDF, a lightweight PDF, XPS, and eBook viewer, renderer, and toolkit. Both PyMuPDF and MuPDF are maintained and developed by Artifex Software, Inc.
MuPDF can access files in PDF, XPS, OpenXPS, CBZ, EPUB and FB2 (eBooks) formats, and it is known for its top performance and exceptional rendering quality.
With PyMuPDF you can access files with extensions like .pdf, .xps, .oxps, .cbz, .fb2 or .epub. In addition, about 10 popular image formats can also be handled like documents: .png, .jpg, .bmp, .tiff, etc. -
tabula-py is a simple Python wrapper of tabula-java, which can read tables in a PDF. You can read tables from a PDF and convert them into a pandas DataFrame. tabula-py also enables you to convert a PDF file into a CSV, a TSV or a JSON file.
-
Camelot is a Python library that can help you extract tables from PDFs.
pdfplumberPlumb a PDF for detailed information about each char, rectangle, line, et cetera — and easily extract text and tables.
If you need to extract data from image PDF files, it's a whole different story, and you might need to use OCR libraries like (Py)Tesseract or other tools.
Have some specific data conversion / extraction needs? Please contact me for consulting - a little script can probably automate hours of manual processing in a few seconds!
← Other articles
 twitter
twitter email
email github
github linkedin
linkedin freelancing
freelancing